Data quality audit: why do AI projects fail?
AI
Data quality audit: why do AI projects fail? | Syneo
How do AI projects fail due to poor data? Practical data quality audit framework: what to measure, AI-specific errors (label, leakage, drift), and specific deliverables for improvement.
data quality, data quality audit, AI, labeling, training-serving-skew, drift, dataops, compliance, RAG, LLM, data governance
February 21, 2026

AI projects are spectacular, but ruthlessly pragmatic: if the input data is incorrect, incomplete, delayed, or incomparable, the model will make bad decisions. In such cases, the team often suspects a "model error," but in reality, the raw material has deteriorated. Data quality auditing is critical because it quickly determines whether a given use case is even feasible with acceptable risk, and if so, what needs to be fixed first.
This article provides you with a practical audit framework: what to measure, what typical AI-specific data quality issues companies encounter, and what tangible deliverables to request from your team or supplier.
Why do AI projects fail due to data quality?
The problem of data quality rarely manifests itself as "bad data." Rather, it manifests itself as:
The pilot demo works, but accuracy deteriorates in live operation.
the business does not trust the output, so it bypasses the system
The launch is delayed for weeks because "another data source" needs to be added.
The model is "smart," but its impact cannot be measured (no baseline, no instrumentation).
compliance or data protection risks are discovered too late
Bad data also has direct costs. According to a widely cited estimate by Gartner, poor data quality costs organizations an average of $15 million per year (due to bad decisions, rework, and lost revenue). Source: Gartner press release.
With AI, the situation is even more difficult because the error does not "only" appear in the report. The model learns the incorrect pattern , scales it up, and automates it.
What does data quality mean through AI glasses?
Many organizations approach data with BI (reporting) logic: if the dashboard is "roughly good," then the data is good. With AI, however, the yardstick is different.
1) The "correct value" alone is not enough
The field may be accurate, but:
no timestamp or wrong time zone (critical for time-series use cases)
no stable key (customer, machine, product identification)
the same code has different meanings in different systems (conceptual inconsistency)
2) Labeling and target variable (label) quality
In supervised learning (e.g., error detection, SLA prediction, churn), the label is the most expensive data. If the label is:
is recorded inconsistently
modified retrospectively (reversal, complaint)
actually proxy (does not measure the "real" target)
then the model will not learn what you want it to learn.
3) AI-specific pitfalls
These are often only noticed during audits:
target leakage: the input variable actually contains information about the future
training-serving skew: the feature is formed differently during training than in production
sampling bias: the training data does not represent the real world
drift: the process changes over time, the data shifts
Data quality audit vs. data cleansing: what's the difference?
The audit is a diagnosis. Its purpose is not to "beautify" everything, but rather to:
assess the current status (profiling, statistics, error rates)
identifies the causes (process, integration, master data, human recording)
convert errors into business risk (how much does it cost)
assign repair backlog and priority (what to repair first)
Data cleansing is only worthwhile if, after the audit, the use case appears to make business sense and the cost of the correction is proportionate to the expected benefit.
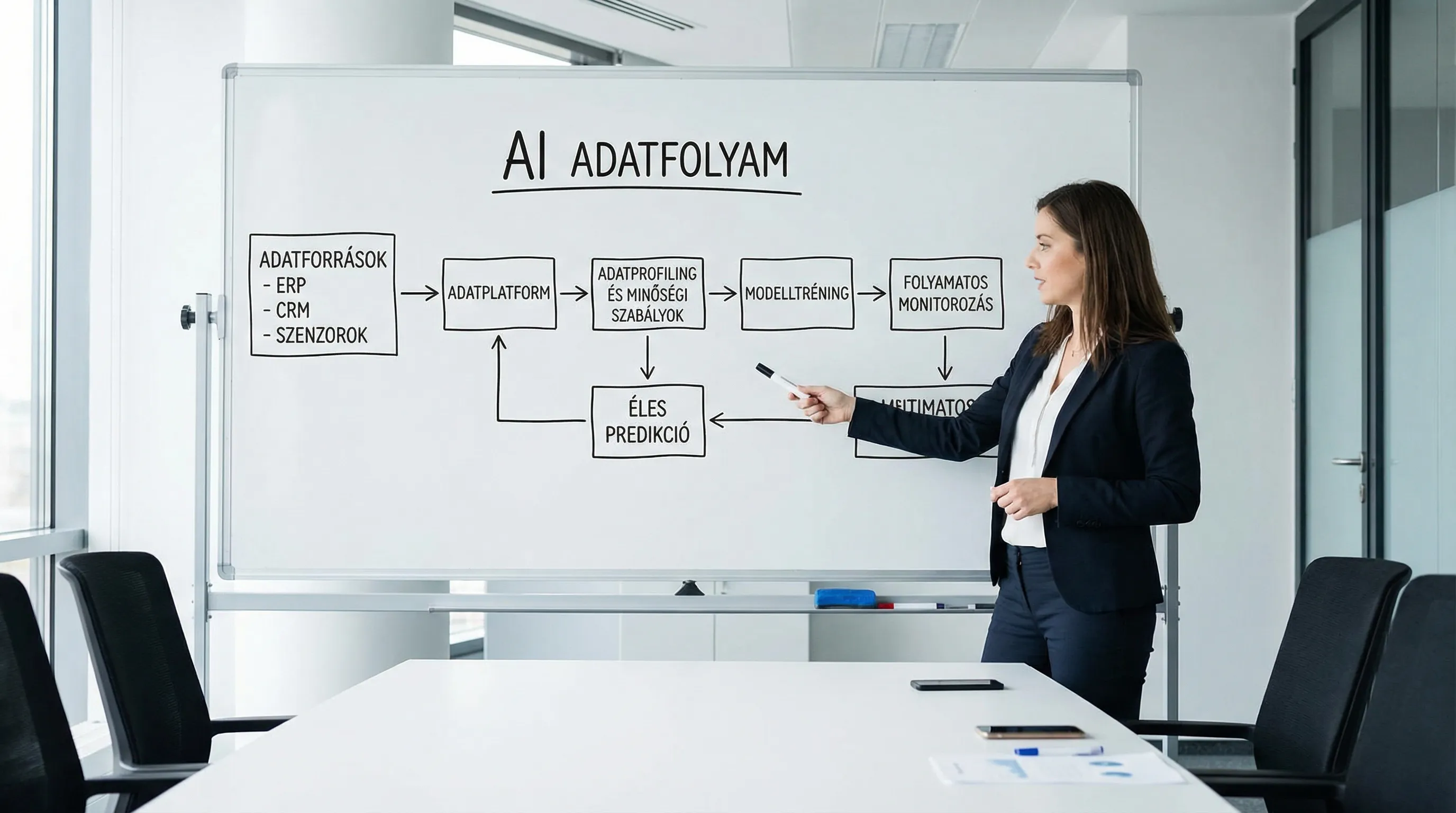
A proven data quality audit framework (for AI projects)
The following logic works well for SMEs and large companies alike, in ERP/CRM, manufacturing, and customer service use cases.
1) Clarification of use cases and decision points
Even without an audit, this is the "hidden" flaw in most projects. Clarify:
what decision the AI supports (e.g., approval, prioritization, alert)
who uses it, how often, under what SLA
What is the measure of success (often business KPIs are needed instead of accuracy)?
If the goal and KPI are not right, it is worth going back to measurability and risks. Syneo's guide provides a good basis for this: Planning a digitalization project: goals, KPIs, risks.
2) Mapping data inventory and data lineage
With AI, it is typical for data to come from "many small pipes." At a minimum, there should be:
list of data sources (ERP, CRM, Excel, machine data, ticketing)
update frequency and delay
keys and connection logic
where the transformation takes place (ETL/ELT, manual export)
3) Profiling: facts instead of hunches
Profiling is a quick reality check. This is where we find out what the statement "we have data" means in practice.
Measure at least:
deficiency (null/empty ratio)
duplication (same key, different content)
range and format (validity)
consistency between systems (e.g., statuses, code lists)
time series completeness (omissions, burst nature)
4) AI-specific data quality tests
In addition to the classic dimensions, it is worth conducting AI-tailored tests:
Area | What should you measure? | What goes wrong in AI? | Typical repair |
Label quality | inter-annotator agreement, label stability, late corrections | the model is optimized for the "wrong purpose" | labeling guidelines, sampling audit, label workflow |
Leakage risk | feature and label chronology, "too good" predictions | wonderful accuracy in the pilot, failure in real life | time slicing, feature blacklist |
Training-serving discrepancy | Definition of feature training in teaching vs. in practice | unpredictable drift, wrong decisions | feature store or data contract |
Representativeness | segment coverage, proportion of rare events | distortion, blind spots | targeted data collection, stratified sampling |
PII and compliance | presence of personal data, minimization | GDPR risk, legal stop | pseudonymization, access control |
5) Root cause analysis and repair backlog
This is where the greatest value lies: not in the fact that "there is a 20% shortfall," but in why this is the case and how it will be turned into a project task.
Good audit output:
cause-and-effect map (process, system, person)
Prioritized backlog (business damage, repair costs, dependencies)
data owners, system owners
Quick wins (errors that can be corrected within 1-2 weeks)
6) Monitoring and quality SLA integration
It is not enough to simply "deliver" an AI system. It must be operated, and data quality is part of that operation.
The minimum package:
data quality dashboard (error rates, refresh rates, duplication)
alerts with thresholds (e.g., deficiency above 2%)
change management (if the meaning of a field changes, don't silently break the model)
This is closely related to DataOps and DevOps thinking. If you want to get organized on the delivery and deployment side, here's some useful context: DevOps Basics: The Road from Zero to Production in 2026.
Typical data quality errors that hurt AI the most
ERP and finance
multiple product codes for the same product (master data problem)
"fluctuating truth" due to subsequent cancellation and reversal
different code lists for each site
CRM and sales
duplicate customers (separate email, separate company details)
Missing or too loosely filled in industry, size, status fields
"Dead leads" are not closed, distorting churn and conversion models.
Related topic where data and processes go hand in hand: CRM implementation checklist: data, processes, training.
Manufacturing and predictive maintenance
time synchronization error in sensor data (even a minute-level deviation is sufficient)
event log and maintenance ticket cannot be linked with a key
alarm fatigue: too many poorly categorized alarms
If you are looking at PdM use cases, it is worth noting: Predictive maintenance: how to reduce machine downtime.
LLM, RAG, and knowledge base (document-based AI)
Here, data quality slips not on tables, but on documents:
duplicate, conflicting versions (which one is "true"?)
incorrect metadata (date, product line, language)
PII or confidential information "slips" into the knowledge base
What should you ask for at the end of a data quality audit? (specific deliverables)
"You'll get a report" is not enough. An audit is only good if it can be translated into action.
Deliverable | What does it contain? | What is it good for when making decisions? |
Data inventory and lineage outline | sources, transformations, updates, keys | dependencies and bottlenecks are visible |
Profiling results | incompleteness, duplication, validity, consistency | objective description of the situation, not an opinion |
Critical Data Elements (CDE) List | without which there is no use case | focus, scope control |
Quality ruleset | measurable rules and thresholds | basis for subsequent automated monitoring |
Repair backlog and priority | tasks, owner, estimated impact | roadmap and resource planning |
Risk and compliance findings | PII, access, retention, legal basis | late "legal stop" can be avoided |
How big of an audit is needed, and when is it worthwhile?
Practical approach in 2026:
Quick AI-ready data quality assessment: when deciding whether to launch a pilot. Goal: validate 1-2 use cases, filter out high risks.
Detailed audit and data correction program: when the pilot is commercially promising and you want to scale up. Goal: stable data flow, monitoring, governance.
The return on investment does not usually come in the form of "better data," but rather in faster systems, less rework, and the business's trust in AI.
Quick self-check: 10 minutes before an AI project
If you only have time for a quick sanity check, these six questions can prevent many failures:
Is there a clear owner of the data (both on the business and IT sides)?
Is there a stable identifier that can be used to connect the systems?
Do you know the ratio of incomplete and duplicate records in critical fields?
How are labels (if any) generated, and how consistent are they?
Can data refresh and delay be measured (not just "in theory")?
Do you know where personal data is located and what the legal basis and minimization are?
If you are unsure about several points, a data quality audit is typically the most cost-effective step to take to get a clear picture.
Frequently Asked Questions (FAQ)
What is the most common reason why AI pilot works in practice but not in real life? Most often, it is because the pilot data is "hand-picked" or cleaned up afterwards, but in real life, the refresh rate and definitions are different, and drift or incomplete data appears.
What are the minimum data quality indicators that should be measured? Completeness, duplication, validity (format and range), consistency between systems, as well as updates and delays. In AI use cases, label quality should also be measured separately.
Is it possible to implement AI without a data quality audit? Yes, but there is a high risk that the project will be delayed due to data problems that arise later, or that it will not be adopted due to a lack of trust. Audits are typically the cheapest form of risk mitigation.
Does data quality matter in the case of RAG and corporate chatbots? Yes. Here, data quality refers to document version management, metadata, duplication, and the filtering of confidential data. A poor knowledge base can confidently give the wrong answer.
When is it worth starting data correction? When, after the audit, it appears that the correction of critical errors is proportional to the expected business benefits, and there is a designated owner and a measurable quality SLA for maintenance.
Next step: AI-aligned data quality audit with Syneo support
If you are planning an AI project (whether based on ERP/CRM data, manufacturing, or document-based knowledge bases), a data quality audit will help you quickly clarify what can be built safely and what requires data and integration work first.
Syneo supports the audit, the creation of a repair backlog, and the planning of the technical foundations necessary for implementation with its IT and AI consulting experience. For details and consultation, visit the Syneo website.
