DevOps framework for SMEs: roles and KPIs
Other
DevOps framework for SMEs: roles and KPIs | Syneo
Practical DevOps framework for SMEs: roles, responsibilities (PO, Tech Lead, Platform, Service Owner, Security), KPI recommendations, and a 90-day implementation plan for measurable improvement.
DevOps, SME, KPI, RACI, DevSecOps, SLO, CI/CD, observability, operations, culture
March 9, 2026

For most SMEs, the introduction of DevOps fails not because they "don't have enough tools," but because they lack a common operating framework: who is responsible for what, what do we consider complete, and how will we know in four weeks that we have actually become faster and more stable?
A DevOps framework for SMEs is not a corporate "process template," but rather an easily maintainable operating model: a few clear roles, a couple of metrics (KPIs), and a short feedback cycle that aligns development and operations toward the same goal.
What does the DevOps framework mean in an SME environment?
The DevOps framework typically establishes three things in SMEs:
Roles and responsibilities (RACI logic): who decides, who delivers, who operates, who signs off on the risk.
Metrics and targets: what we measure in flow (transportation), stability (operations), and risk (safety, compliance).
Rhythms: weekly, biweekly, monthly reviews, lessons learned after incidents, release governance.
Important: this is not the same as CI/CD. CI/CD is the "engine," while the framework is the minimum set of rules that keeps the engine from falling apart and working against the organization.
If you would like a comprehensive, in-depth technical guide to DevOps core processes, Syneo has a separate resource dedicated to this topic: DevOps Basics: The Path from Zero to Production in 2026.
The "minimum viable" DevOps operating model for SMEs
In the case of SMEs, it is rarely realistic to have a separate Platform Team, a separate SRE team, and a separate Security Engineering team. The goal is rather to have the same tasks, even with combined roles.
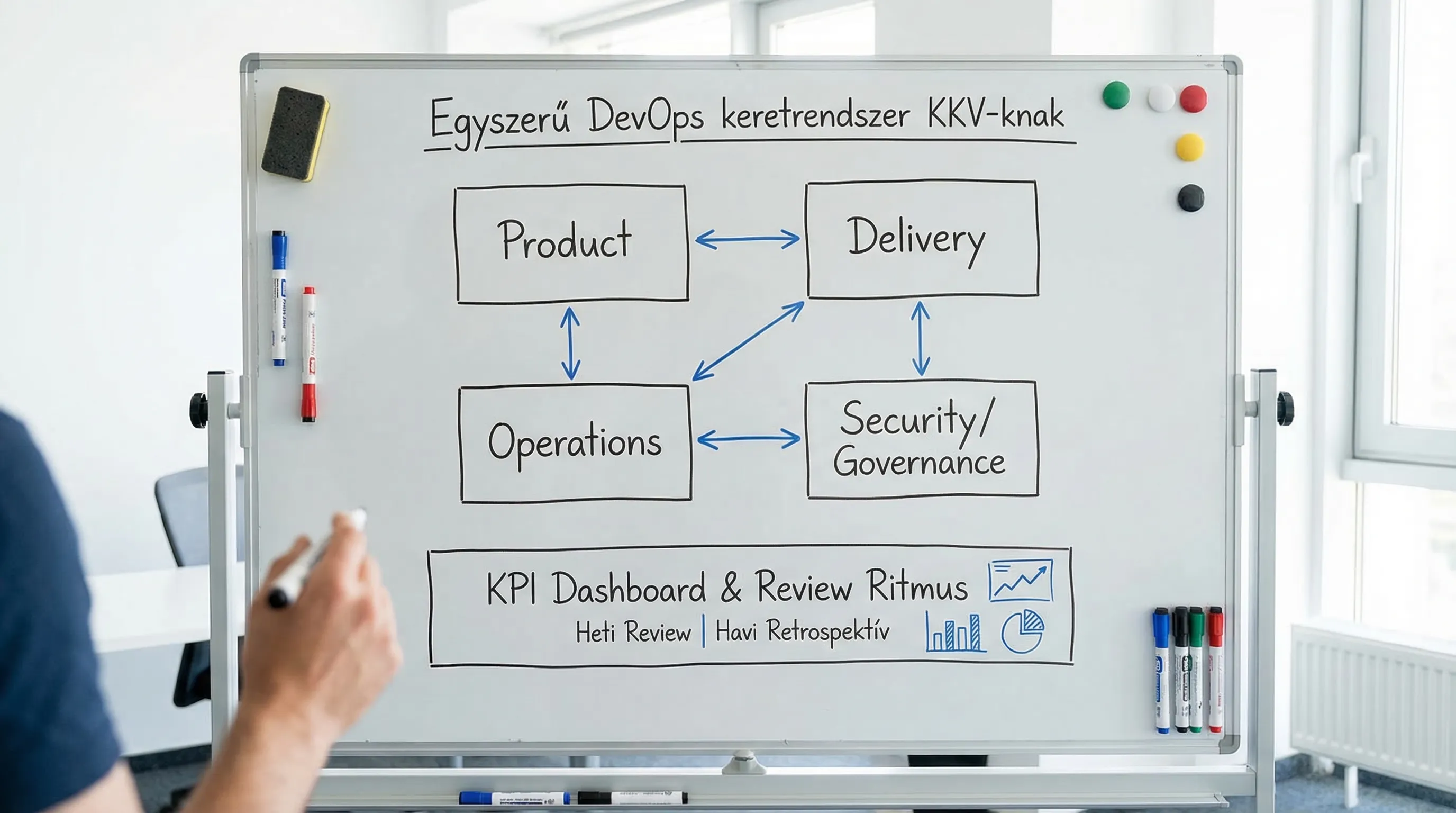
It is worth thinking in terms of four layers:
1) Business focus (Product)
What is the product/service (including internal systems), and who owns it?
What is the desired business outcome (lead time, cost, SLA, revenue, compliance)?
2) Delivery capacity
How does a need become a radical change?
What counts as "done" (Definition of Done), what is the release policy?
3) Operability (Operations / Reliability)
What are the SLOs (service level objectives)?
Incident management, on-call, root cause, preventive backlog.
4) Risk and control (Security / Governance)
What are the minimum security gates required (DevSecOps)?
Can it be audited who made what changes, when, and with what approval?
A framework is good if it means less uncertainty rather than more administration.
Roles: who should be assigned, even if there is no specific person for the job?
In SMEs, it is common for one person to wear several hats. Even so, it is worth linking responsibility to a specific name, because otherwise KPIs will become "ownerless."
Basic roles (required almost everywhere)
Product Owner (or business owner)
Priority, scope, business KPIs.
Deciding what is "worth it" and what is "nice to have."
Tech Lead (or Engineering Lead)
Architectural decisions, technical debt management.
Engineering standards (code review, branching, quality gates).
DevOps/Platform Manager (even if part-time)
CI/CD, IaC, pipeline templates, environments, accesses.
Simplification of the developer "path" (golden path approach).
Service Owner (operations manager)
SLOs, incident process, monitoring, on-call.
Incorporating lessons learned after incidents.
Security owner (DevSecOps owner)
Minimum controls in build and release.
Prioritization of vulnerabilities and repair SLAs.
SME reality: combined roles
The Tech Lead may also be responsible for the Platform for a period of time, but in this case it is particularly important to record KPIs and weekly capacity.
The Security Owner can be an IT security manager or an external partner, but an internal "host" is required.
Simple RACI template (1 product / 1 team)
Decision-making/operational area | Responsible (does) | Accountable | Consulted (to be involved) | Informed (to be informed) |
Priority and release scope | PO | PO | Technical Lead, Service Owner | Stakeholders |
CI/CD pipeline standard | Platform manager | Technical Lead | Security owner | Dev team |
SLOs and alerts | Service Owner | Service Owner | Technical Lead | PO |
Incident management and postmortem | Service Owner | Service Owner | Tech Lead, Platform Manager | PO |
SAST/SCA/IaC scanning policy | Security owner | Security owner | Platform manager | Tech Lead, PO |
Go-live approval (risk) | Technical Lead | PO (business risk), Service Owner (operational risk) | Security owner | Stakeholders |
If you want to objectively assess your DevOps maturity level, it is worth starting with a structured assessment: DevOps maturity assessment: where does your team stand?
KPIs: what should you measure to ensure you get business results rather than just a "pretty dashboard"?
A good KPI package for SMEs is small but covers multiple perspectives. Practical breakdown:
Flow KPIs: how fast and how often we deliver.
Stability KPIs: how reliable the service is.
Risk KPIs: security, compliance, rollback requirements.
In the world of DevOps, DORA metrics (deployment frequency, lead time for changes, change failure rate, time to restore service) are commonly used to measure flow. For SMEs, these work if you add 2-3 operational and 1-2 security guardrails.
Recommended set of KPIs (SME-friendly, but usable in real-world situations)
KPI | What does it indicate? | How can you measure it easily? | Typical frequency |
Frequency of deployment | Delivery frequency | Number of prod deploys per week | Weekly |
Lead time for changes | How long does it take from idea to sharp? | Start of ticket "In Progress" and between prod deploy | Weekly/monthly |
Change failure rate | Quality of changes | Linked to a prod incident or rollback change | Monthly |
Time to restore service (MTTR) | Operational responsiveness | Start of incident and recovery time | Monthly |
SLO fulfillment (e.g., availability, latency) | Customer experience and stability | Monitoring from SLI, error budget | Weekly |
Alert noise (alarm/quality ratio) | Operational load | Total alarms vs. alarms requiring action | Weekly |
Critical vulnerability fix time | Safety discipline | CVSS critical "open" time (SLA) | Weekly/monthly |
Pipeline success rate | Delivery reliability | CI run pass rate | Weekly |
Incident follow-up closure rate | Does learning become ingrained? | Postmortem action items closed % | Monthly |
Note: Many teams immediately start measuring coverage, story points, and lines of code. These can easily lead you astray. The advantage of the above package is that it can be directly linked to delivery speed, stability, and risk.
KPI target values: what should the target be?
For SMEs, the safest approach is to start with the baseline and then move on to the trend target.
Measure without change for 2-4 weeks (baseline).
Then set a quarterly goal that is realistic given your capacity.
Examples that generally work (not an industry benchmark, but a practical goal):
Lead time: "from weeks to days," starting with eliminating the top three causes (manual release steps, unstable environments, overly large batches).
Change failure rate: initially, making incidents related to changes visible, then reducing them (better test gates, feature flags, canary).
MTTR: measurable reduction with playbooks and better observability.
KPIs only work if there is an "operational rhythm" associated with them.
In a functioning DevOps framework, KPI reviews do not mean a tsunami of extra meetings. A simple rhythm is enough:
30 minutes per week: flow and operational indicators (deployment frequency, pipeline failure causes, alert noise).
60 minutes per month: trends, SLO, vulnerability status, top 3 interventions for the following month.
After every serious incident: a brief postmortem (not a search for a scapegoat) and 1-3 specific actions.
This is where the importance of roles comes in: if there is no designated Service Owner and Security Owner, the monthly review becomes a "nice to have" list.
Analogy from service providers: why are role and KPI important together?
For a residential on-site service provider (e.g., door, gate, maintenance), the promise of "fast response" is not a motivational poster, but an operating system: dispatcher, parts logistics, first-time fix rate, response time.
The same logic applies in IT. If your commitment is to deliver quickly and securely, then you need roles (who is responsible for being on call, who is the release owner) and you need measurement. A good example is the same-day delivery service model, where capacity and response time are part of the competitive advantage: residential garage door specialists.
The lesson for SMEs: DevOps KPI is not an "IT KPI" but a service capability.
Common pitfalls for SMEs (and quick remedies)
KPI theater: we measure everything, but nothing changes
Typical sign: there is a dashboard, but no decision.
Countermeasure: Have a predefined response for every KPI: "If it deteriorates, what do we do?"
Local optimization: fast deployment, but more incidents
Typical sign: deployment frequency increases, but change failure rate deteriorates.
Countermeasure: mandatory stability guardrail (SLO, MTTR) alongside flow KPI.
No ownership of the platform
Typical sign: the pipeline "belongs to someone," but no one prioritizes it.
Countermeasure: Name the person responsible for the platform and give them dedicated capacity (even if it's only half a day per week).
Security "at the end," audit "as a surprise"
Countermeasure: DevSecOps minimum gates (SAST/SCA/IaC scanning, secrets management, artifact management). If you need more detailed, practical implementation, a separate guide is useful: DevSecOps in practice: how to build secure CI/CD.
90-day implementation framework: focus on roles and KPIs
The goal here is not to have "perfect DevOps" in 90 days, but to have measurably better delivery and operations, and for management to believe it because they can see the data.
0–30 days: designation, baseline, minimum measurement
Assigning roles by name (PO, Tech Lead, Platform, Service Owner, Security Owner).
Defining KPIs (what counts as a deployment, what is an incident, when does lead time start).
Baseline measurement, simple dashboard (even ticketing + CI logs + monitoring).
31–60 days: 2–3 interventions that drive KPIs
1 intervention in the flow (e.g., release automation, batch size reduction).
1 intervention on stability (alarm noise reduction, clarification of SLOs).
1 intervention on the risk (secrets management, dependency scanning, fix repair SLA).
61–90 days: simplifying governance, setting the pace of decision-making
Make monthly KPI reviews a routine.
Postmortem actions closure discipline.
Setting targets for the next quarter relative to the baseline.
How can Syneo help with this?
Syneo typically delivers rapid value for SMEs and mid-market companies where DevOps has been "technically launched" but the organization is not yet able to manage and measure it effectively:
clarification of roles and responsibilities (RACI),
Establishing KPIs and SLOs, baseline and measurement methodology,
Aligning DevOps and DevSecOps operations with project delivery and operations.
If you feel that you have a pipeline and monitoring in place, but delivery is still unpredictable, then the best next step is usually a short assessment and a 30-90 day action plan. A good starting point for this is the DevOps maturity assessment, because it does not provide a list of tools, but rather prioritized interventions based on the measured data.
