Ops DevOps: Where is the line between operations and development?
Other
Ops DevOps: Where Is the Line Between Operations and Development? | Syneo
What does the boundary between Ops and Dev mean? Service ownership, RACI, SRE, platform engineering, and 30-day practical steps for cleaner, faster delivery.
Ops, DevOps, SRE, platform engineering, service ownership, RACI, observability, CI/CD, IaC, DevSecOps, DORA, on-call
April 1, 2026

The “Ops vs. Dev” debate is rarely actually about technology. Rather, it’s about who takes responsibility for the entire lifecycle of a service and how you ensure that changes are deployed quickly yet in a controlled manner.
In the reality of 2026, with the cloud, containers, IaC, CI/CD, and an increasing number of automated components, traditional boundaries are blurring. But that doesn’t mean everyone will be “DevOps.” DevOps is when operations (Ops) and development (Dev) work together to optimize toward a common goal: delivering at a business-sensible pace, with low risk, and operating stably.
What do "Ops" and "Dev" actually mean in practice?
Ops (Operations): Service operation and risk management
Ops typically does not “deal with servers,” but rather operates services. This includes:
Availability and Incident Management
monitoring, alerts, capacity and cost control
backup/restore, disaster recovery (DR) readiness
patching, configuration, access, and permissions
Operational runbooks, change management, SLAs
Dev (Development): Delivery of business capabilities and quality
The goal of a Dev is to deliver value, but in modern product development, this no longer stops at "delivering the code." Typical responsibilities:
Development of features, APIs, data models, and integrations
testability, releaseability
bug fixes, performance optimization
Development of versioning, build, and deployment processes
(ideally) providing the metrics and logs needed for diagnostics
The conflict arises when Dev feels they’re “done,” while Ops feels “the work is just beginning.”
Ops DevOps: Where Do You Draw the Line If You Don’t Want Chaos?
DevOps does not mean erasing boundaries, but rather clearly defining them: what remains the specialized responsibility of Operations, and what is the inalienable responsibility of the development team.
In the most effective organizations, the boundaries lie not between roles but along lines of service ownership.
The "who owns the service?" principle
A simple, effective set of questions:
Who takes responsibility if the system is down at 2 a.m.?
Who can safely roll back to the last release?
Who has the right to make changes, and who is responsible for the consequences?
Who writes and maintains the runbook?
If there is no clear answer to these questions, then “DevOps” is really just a label.
The most common operating models (and where they tend to go wrong)
1) Classic handoff: Dev develops, Ops operates
This is still the case in many ERP/CMS/CRM and integration environments today.
Advantage: clear operational focus, easily configurable operational controls
Risk: slow release, many misunderstandings, “throwing it over the wall” (you build it, they run it instead of you build it, you run it)
2) “You build it, you run it”: the team also handles on-call duties
This is common in product and digital teams.
Advantage: quick feedback, better quality, less "that's not my job"
Risk: without a platform and guardrails, developers will burn out and operations will become ad hoc
3) SRE (Site Reliability Engineering): reliability with measurable goals
SRE treats reliability as an engineering problem, focusing on SLOs, error budgets, and automation. A classic starting point is the Google SRE book (also available for free online): *Site Reliability Engineering*.
Advantage: clear set of objectives (SLO), effective decision-making mechanism (error budget)
Risk: Without SLO, just renamed Ops
4) Platform engineering: internal platform team, product teams operating on a self-service basis
The platform team "provides services" to developers: CI/CD templates, logs/metrics/tracing, secrets, IaC modules, and standard environments.
Advantage: scalable, reduces cognitive load
Risk: If the platform team turns into a ticket factory, manual handoffs will return
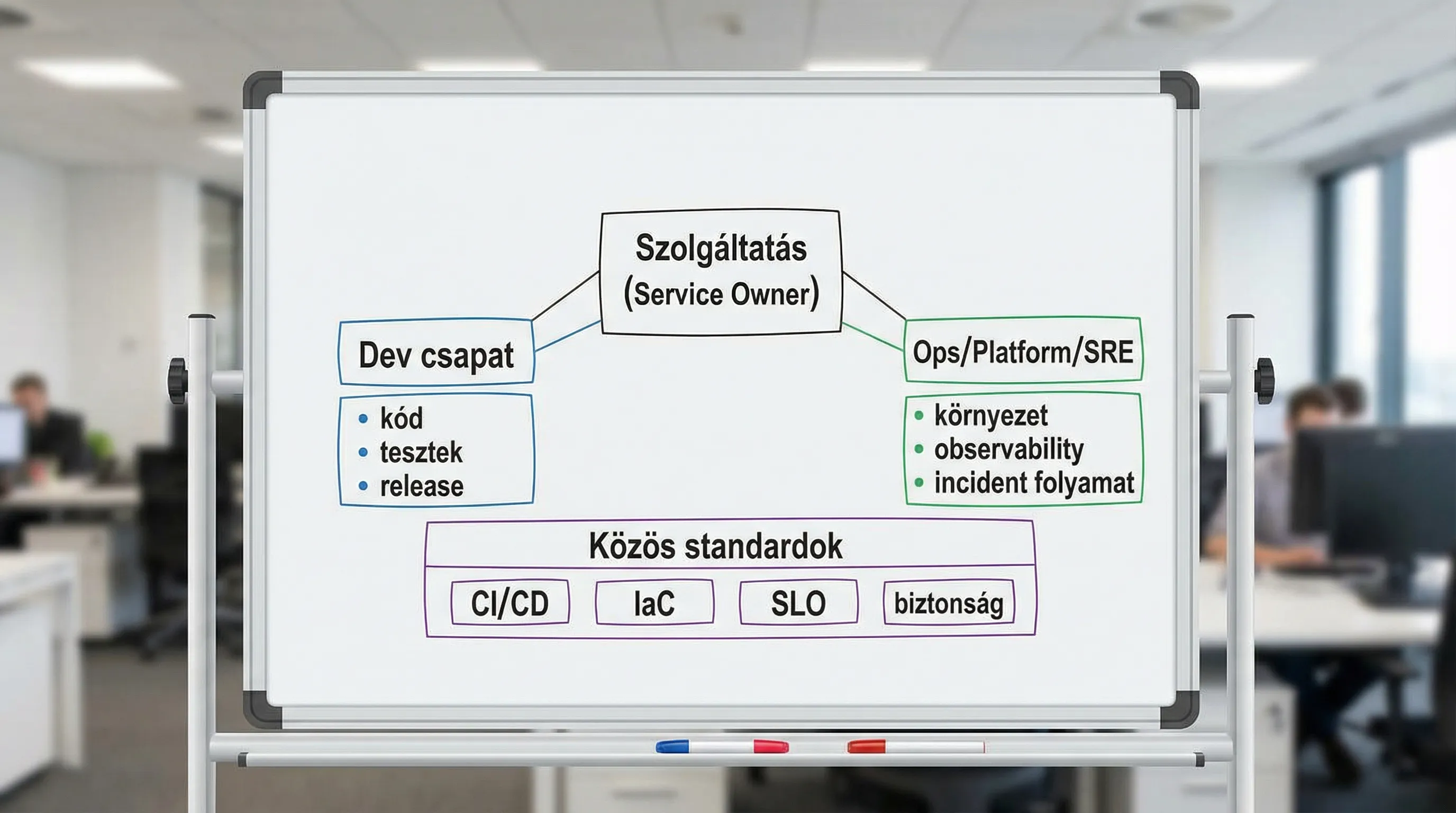
A Clear Demarcation: Responsibilities from Delivery to Operation
The table below shows a typical, effective classification. It is not an "absolute truth," but it is a good starting point for settling disputes.
Area | Dev's primary responsibility | Primary responsibilities of Ops/Platform/SRE | Common Ground (DevOps) |
CI (build, unit tests) | pipeline logic, tests, quality gate | runtime environment, runner hardening | standardized templates |
CD (deployment) | release strategy, feature flag, rollback | environments, policies, access | automated, auditable issuance |
IaC and Environments | Proper use of modules, app configuration | IaC modules, guardrail, landing zone | based on infrastructure code |
Observability | app metrics, domain logs, trace points | central stack, alerting standard | SLI/SLO and Alarm Hygiene |
Incident management | repair, RCA technical content | process, on-call system, post-mortem procedure | blameless learning |
Security (DevSecOps) | code and dependencies, secure-by-design | secrets, IAM, hardening, logging | automated checks in the pipeline |
If the team agrees on this table, it immediately becomes clear that the “boundary” is not a single line, but rather a series of connection points that can be smoothed out through standards and automation.
The RACI matrix is the most powerful DevOps tool, yet we rarely talk about it
Most Ops-Dev conflicts aren’t caused by ill will, but by unclear decision-making authority. A one-page RACI matrix can save months of debate.
Event / Decision | Responsible (will do it) | Accountable (assumes responsibility) | Consulted (to be involved) | Informed (to be informed) |
Approval of the production release | Dev team | Service Owner | Ops/Security | Affected store |
Incident triage (P1) | On-call (Dev or SRE) | Incident Commander | Ops, Dev, Vendor | Stakeholders |
Rollback decision | On-call + Dev Lead | Service Owner | Oops | Store |
Defining SLO objectives | Service Owner | IT Management | Dev, Ops, Business | Stakeholders |
The bottom line: appoint a Service Owner—who isn’t necessarily from Ops or Dev—but who is responsible for the service’s business and technical operations.
7 Signs That Your Boundary Is in the Wrong Place
Serious mistakes turn into a blame game (whose fault it is), rather than a learning experience.
Releases are infrequent, but they are major and risky.
There is a lot of manual, document-based environmental management.
There is no uniform monitoring standard, and the alerting system is noisy.
In the end, security ends up "taking over" the process because there is no DevSecOps foundation.
Ops is swamped with tickets, and Dev is swamped with on-call duties.
There are no objective metrics for delivery (DORA) and stability.
The DORA (DevOps Research and Assessment) metrics provide a solid, industry-benchmarkable foundation for discussion; see the DORA resources page.
How can you set boundaries while also speeding up delivery?
1) Make decisions at the service level, not at the team level
The question shouldn’t be “whether to focus on operations or development,” but rather:
which services are critical,
what kind of SLO should be maintained,
What is our rollback strategy?
who is on call and what we are automating.
2) Standardize the platform so that no team is a “one-of-a-kind snowflake”
The key to scaling DevOps is a platform-based approach: self-service, templates, and guardrails.
If you need a framework for this, here’s a helpful resource from Syneo: DevOps Framework for SMEs: Roles and KPIs.
3) Mandatory minimums: observability and maintainability as part of the Definition of Done
"Done" shouldn't just be a feature. It should at least include:
basic metrics (latency, error rate, throughput)
structured logging and correlation ID
Runbook and rollback description
alert rules (not every log entry triggers an alert)
4) Security: not a barrier, but built-in controls
DevSecOps works when security isn’t a separate “gate” but rather consists of automated checks and a robust access control model.
Related detailed guide: DevSecOps in Practice: How to Build Secure CI/CD.
5) Without metrics, there are only opinions
Claims such as “delivery is slow” or “the system is unstable” should be backed up with a set of basic metrics.
Delivery: deployment frequency, lead time for changes
Stability: failure rate, MTTR
If you’d like to assess this in a structured way and turn it into an action plan: DevOps Maturity Assessment: Where Does Your Team Stand?
Quick, 30-day steps toward clearer boundaries (without drawing an org chart)
Week 1: Clarifying ownership and incident management processes
Choose 1 critical service and record it:
Service Owner
on-call model
rollback authority
P1 Incident Communication Channel
Week 2: Minimum Observability Package
Ensure consistent implementation:
dashboard (SLIs)
3–5 valid alarms
logos and trace bases
Week 3: Release Guardrail
Pipeline gates instead of a simple release checklist
automated rollback or, at the very least, a well-practiced rollback
Week 4: Postmortem Routine and Backlog
1-2 Postmortem Templates
Prioritizing tasks (not a document, but a backlog)
If your focus is more on building the entire delivery chain, the article "DevOps Basics: The Path from Scratch to Production in 2026 " is a great place to start.
Frequently Asked Questions (FAQ)
Does DevOps mean the end of operations? No. DevOps is more of an operational model: shared goals, automation, metrics, and clear ownership. In many places, the Ops role is evolving toward platform/SRE.
Who should be on call: Dev or Ops? The right answer depends on the service. For critical, rapidly evolving products, Dev often takes the lead (with SRE support). In integration- and compliance-sensitive environments, a hybrid approach is common, where Ops/SRE handles the first line of support and Dev the second.
What is the difference between SRE and DevOps? DevOps is a broader philosophy and collaboration model. SRE is a specific, engineering-focused approach to reliability (SLOs, error budgets, automation).
What makes the boundary between Dev and Ops healthy? It’s clear accountability (Service Owner, RACI), established standards (platform, IaC, CI/CD), and decisions based on metrics (DORA, SLOs, MTTR).
When should you bring in an external consultant for Ops/DevOps? If releases are risky, there are many recurring incidents, there are no consistent operational standards, or you want to clarify operational feasibility and responsibilities in advance of a major system implementation (ERP/CRM/integration).
Next step: clear responsibilities, faster delivery, fewer incidents
If the “Ops vs. DevOps” debate is a recurring topic at your organization, it’s worth starting with a brief, structured assessment: service ownership, RACI, key metrics, and identifying the biggest risk areas. The Syneo team can assist you with IT consulting, DevOps and operations design, as well as the planning of automated CI/CD and DevSecOps frameworks.
To get in touch or schedule a meeting: Syneo, or find out when it’s worth bringing in a consultant: IT consulting: when is it needed, and what do you get in return?
