DevOps work items: How to build a well-measurable backlog
Other
DevOps Work Items: How to Build a Well-Measurable Backlog | Syneo
A Practical Guide to DevOps Work Items: How to Build a Clear, Measurable Backlog (Hierarchy, Required Fields, Metrics, Workflow, and a 30-Day Implementation Plan).
DevOps, work items, backlog, measurability, KPI, DORA, CI/CD, observability, technical debt, workflow
March 31, 2026

When implementing DevOps, many teams quickly move on to CI/CD, only to get stuck on the next question: what should we put in the backlog to ensure that it results in truly measurable, predictable delivery? This is where DevOps work items come into play—structured backlog items that link business goals, development work, releases, and metrics.
If a work item is simply labeled “API fix” or “login bug,” then while there will be a task, there won’t be management-level transparency, and often there won’t be any verifiable results either. If, on the other hand, they are well-structured, the work item serves as a metric: it clearly shows why we’re doing it, what “done” means, and how we’ll prove it.
The framework below works with both Azure DevOps Work Items and Jira-like systems; the key is taxonomy and measurability.
What are DevOps work items, and why does this hinder measurability?
A DevOps work item is a tracked item (Epic, Feature, User Story, Task, Bug, Change) to which you typically link:
the business objective or outcome (what impact we expect)
the delivery unit (the one that goes live)
the person responsible and the deadline (who is responsible for the decision and the work)
the evidence (tests, logs, dashboards, audit trails)
This is critical because, in DevOps, delivery is not just about “releasing code,” but about measurable value creation. The DORA metrics (deployment frequency, lead time for changes, change failure rate, MTTR), for example, will only be reasonably accurate if the work and the release can be linked to the backlog. To achieve this, order must be established at the work item level.
Further background on the DORA framework: Google Cloud, DORA research.
1) First, decide on the terminology for the backlog: outcome, output, and work
Most teams make the mistake of mixing the following in the same list:
outcomes (business results, such as “reduce the rate of rejected payments”)
outputs (delivered capabilities, such as "3DS2 support")
task (specific activity, such as “rewriting a callback endpoint”)
This confusion can be resolved using the work item hierarchy.
Recommended work item hierarchy (simple, easy to report on)
Epic: strategic initiative (multiple teams, several months)
Feature: A set of capabilities that deliver customer value (more sprints, but still a single focus)
User Story: user value within an iteration (usually within a single sprint)
Task: technical step (1–2 hours or 1–2 days)
Bug: Fix the bug, preferably with an SLA and a reproduction
Azure DevOps: Basics of concepts and fields: Microsoft Learn, Work items.
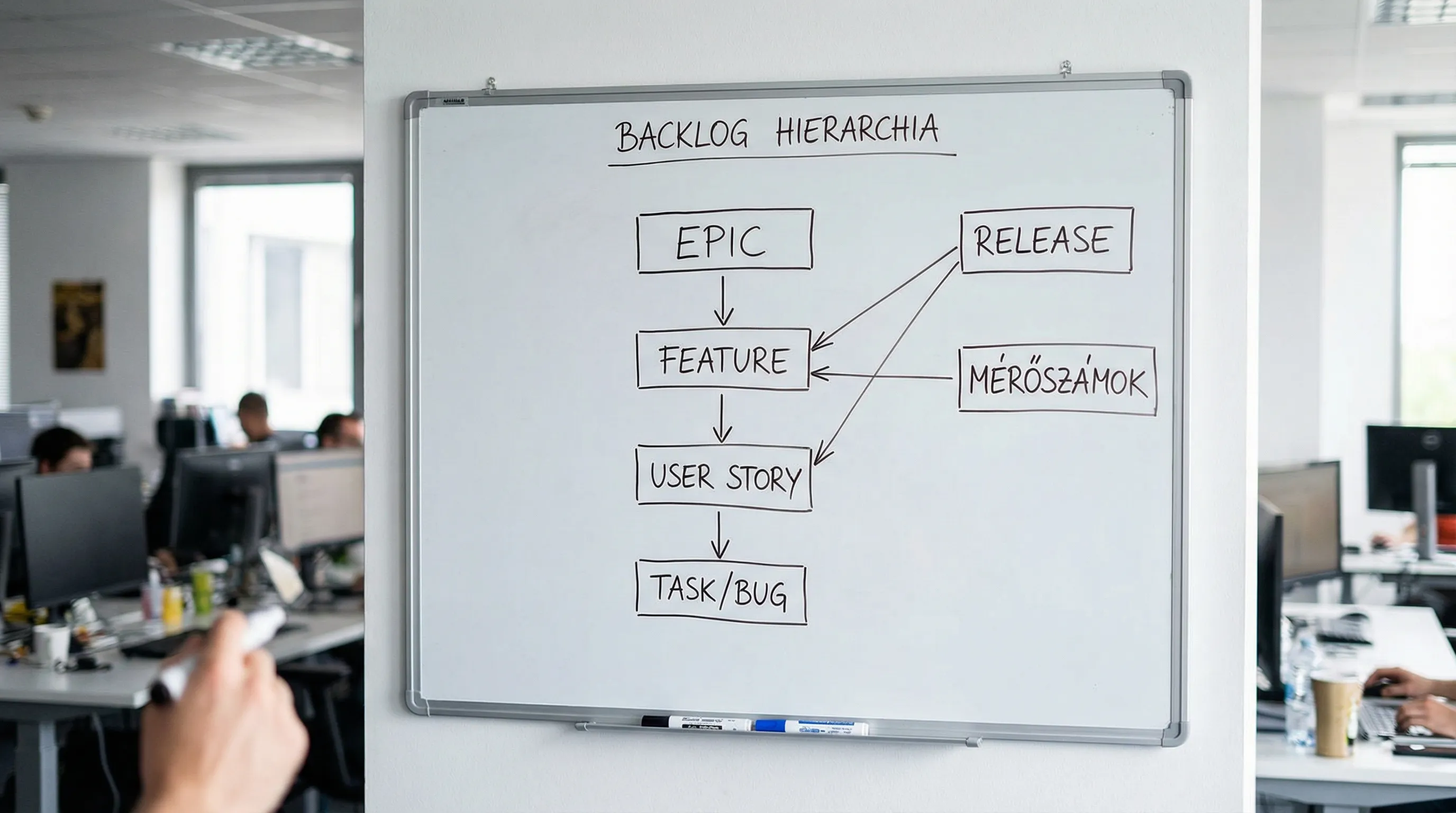
Important rule: management metrics (OKRs, KPIs, ROI) are typically defined at the Epic and Feature levels, while the team’s day-to-day work is defined at the Story/Task/Bug level. If there isn’t a clear link between the two, the metrics will either be too abstract or too technical.
2) Minimum content of a "well-measurable" work item
A backlog isn't measurable simply because it includes story points. It's measurable because it has a clear definition of "done" and you can specify how you'll verify it.
The 6 fields that should be made required
The following are not product-specific; they can be configured as required fields or templates in any work item system.
Field | What is it good for? | A good example | Bad example |
Purpose (why) | Provides context, reduces misunderstandings | “Let’s reduce failed credit card transactions” | “Optimization” |
Scope (what's included, what's not) | Protects the scope and speeds up decision-making | “Web checkout only, no app” | “Pay raise” |
Acceptance criterion (AC) | A testable definition | "The 3DS2 challenge flow completes, and an audit log is recorded" | “Let it work” |
Survey Plan | It demonstrates the outcome | “Dashboard: Failure rate, monitoring period: 2 weeks” | “We’ll see” |
Risk/Dependency | Predicts the cause of the delay | “PSP vendor API limit, rate limit 429” | empty |
Release switch | The basis for Flow and DORA measurements | “Release April 15, 2026, build pipeline link” | empty |
In the table above, the “bad example” is typically bad because it cannot be verified. If the completed state cannot be verified, then the backlog is really just a “reminder list,” not a management tool.
Short template for a user story
The classic "I want to... so that..." formula is a good starting point, but in 2026, it’s worth adding the following to ensure measurability:
Story description: business context in 3–5 sentences
Acceptance criteria: 3–7 testable statements
Measurement plan: which metrics to track, where to display them, what the baseline is, and when to make decisions
Observability tasks: logs, metrics, traces, alerts (if applicable)
In line with this, it makes sense to treat observability as a process rather than an afterthought.
3) Linking the backlog and KPIs: What should you measure, and where should you track it?
The essence of a measurable backlog is that a work item should not merely serve as a way to manage "work," but also as a reference point for measurement. The clearest approach is to define the outcome KPI at the feature level and the technical details of "how to measure" at the story level.
Practical metric mapping (that works for both managers and teams)
Work item level | Typical question | Good metric | Where should it appear? |
Epic | “Is it worth it?” | OKR, ROI, cost, risk reduction | Steering Report, Quarterly Review |
Feature | “Will it have an effect?” | Outcome KPIs (conversion rate, error rate, turnaround time) | Product dashboard |
Story | “Is it ready and working?” | Key Performance Indicators (coverage, error rate, performance budget) | CI/CD, monitoring |
Task | “What needs to be done?” | Run-through, blockers, WIP | Board, Sprint Report |
Bug | “How bad is the pain?” | SLA, MTTR, number of incidents, customer impact | Incident management system, dashboard |
If your team is already using DORA, linking work items significantly improves the reliability of your reports. The article " The DevOps Framework for SMEs: Roles and KPIs" also discusses the core logic of DORA and the DevOps KPI package in the context of Syneo.
4) Statuses, policies, and Definition of Done: this is what makes the backlog reportable
Measurability isn’t just about fields. The workflow is just as important; otherwise, everyone will have a different understanding of what “In Progress” or “Done” means.
A machine in minimal but functional condition
Many organizations overcomplicate things. For an SME or an environment with 1–3 teams, the following is usually sufficient:
New: not yet clarified
Ready: meets the Definition of Ready (DoR)
In Progress: Work in Progress
In Review/Test: PR, QA, security check, UAT
Done: meets the Definition of Done (DoD) and is tied to a release
The key question: What does “Done” mean to you? In many places, it simply means “merge”; in others, it means “production.” For a measurable backlog, it’s worth defining this explicitly:
Story Done: tests passed, acceptance criteria met, observability in place, release scheduled
Feature Done: Live and measurement has started (at least 1 measurement period)
In the case of DevSecOps, it’s a good idea to add security minimums to the DoD (such as SAST/SCA and secrets management). The guide “DevSecOps in Practice: How to Build Secure CI/CD” provides a detailed, practical framework for this.
5) Work item slicing: this is how delivery becomes predictable
One of the hidden prerequisites of a “well-measurable backlog” is that the items must be well-sized. If a story actually takes three weeks to complete, then both the board and the metrics become distorted (false lead time, a lot of “half-finished” work, and blurred accountability).
Fast partitioning heuristics (that work in practice)
Cut vertically: a small but portable unit (UI + API + data) is better than a "refactored API"-style block
One story, one decision: if you need input from multiple stakeholders, break it down into smaller parts
Breaking down metrics: if you need a new metric, log, or dashboard, create a separate task or story for it; don’t leave it implicit
These help ensure that the backlog actually leads to predictable delivery, as confirmed in the article " Project Management in IT: How to Make Delivery Predictable " from the perspectives of KPIs and governance.
6) Bugs, technical debt, and "non-feature" work: how can you make them measurable?
A common problem with backlogs is that “feature” work is well documented, while everything else is a black hole. Yet in DevOps, stability and maintainability are just as much a part of business value.
A minimum requirement may be imposed for bugs
reproduction steps and environment
business impact (how many customers are affected, is there a loss of revenue)
Severity and Target SLA (e.g., P1, P2)
Link to the incident or support ticket
When it comes to tech debt, the key to measurability is: “Which risk does it reduce?”
"Refactor" itself cannot be measured. These, however, can:
“Let’s reduce the build time from 18 minutes to 10 minutes”
“Let’s reduce the change failure rate in the payment module”
“Let’s increase testing coverage along the critical route”
A useful framework for making such decisions regarding legacy system modernization: Modernizing Legacy Systems: When to Refactor, When to Replace?
7) Backlog governance: maintaining a measurable backlog is not a one-time task
Most teams "clean up" their backlog once, only to fall back into the same pattern six weeks later. The reason for this is that they lack a consistent rhythm.
A simple, effective weekly routine
Triage (30 minutes): new bugs, urgent requests, prioritization
Refinement (60 minutes): Clarifying the stories, AC, and metrics for the next 1–2 sprints
Flow review (30 minutes): lead time, bottlenecks, excessive WIP, adherence to the "Done" definition
If you combine this with a quarterly maturity assessment, you’ll quickly see where discipline has broken down. The article “DevOps Maturity Assessment: Where Does Your Team Stand?” provides a good starting point for this.

30-Day Implementation Plan: How to Transition to Measurable DevOps Workitems
Days 0–7: Taxonomy and Templates
Select the hierarchy (Epic, Feature, Story, Task, Bug), and create separate templates for Stories and Bugs. Set up required fields (at least Acceptance Criteria and a measurement plan at the Feature or Story level). At this point, it’s also a good idea to establish the minimum DoR and DoD within the team.
Days 8–14: Workflow and Reports
Simplify the statuses and link work items to PRs, builds, and releases. Set up a minimal dashboard that makes sense for both the team and management: lead time trends, throughput, and 1–2 outcome KPIs for the most important features.
Days 15–30: Governance and Responsibilities
Implement a weekly triage and refinement cycle, and assign responsible parties (the Feature Owner on the product side, and the Story Shepherd or Tech Lead on the technical side). At the end of the month, hold a brief review: which fields were left blank, where were there misunderstandings, and which KPIs were you unable to measure due to missing data or logs?
When is it worth bringing in outside help?
If the backlog is “full” but delivery remains unpredictable, the problem is often not one of capacity, but rather the quality of work items, workflow, and measurement design. In such cases, a short, focused workshop is often faster than introducing a new tool.
The Syneo team supports the development of backlog taxonomies, KPI systems, workflows, and DevSecOps standards in DevOps and IT consulting projects to ensure that work items result in truly measurable deliverables. Details: Syneo.
